Machine Learning Integration with Optimization Models
lecture 12
Author
Harun Pirim
Published
February 12, 2024
Introduction
The following LP we solved in the class assumed that the parameters are known. However, in practice, the parameters are not known and they are estimated from the data. ML models can be used to estimate the parameters. Let’s estimate \(p_i, d_i,s_i\) from the data and solve the LP. These parameters correspond to the profit, demand, and the percentage of demand met for region \(i\). This application illustrates how machine learning can be used to predict parameters of an optimization model. We predict demands, unit profits, and percentage of demand satisfied for 4 regions. We are using the optimization model of Exercise 4.1.
Demand features (20 features):
Historical Sales Data: Past sales figures for the product in each region.
Price: Current and historical prices of the product.
Promotions: Information on past and current promotions or discounts.
Seasonality: Time of year, to capture seasonal effects on demand.
Market Trends: Data on overall market growth or decline.
Competitor Pricing: Prices of similar products from competitors.
Consumer Sentiment: Measures of consumer confidence or sentiment indices.
Economic Indicators: GDP growth rate, unemployment rate, etc.
Weather Conditions: Especially for products sensitive to weather changes.
Special Events: Holidays, sports events, or local festivals.
Product Availability: Stock levels or supply chain issues.
Marketing Spend: Amount spent on advertising and promotions.
Online Search Trends: Volume of online searches related to the product.
Social Media Sentiment: Sentiment analysis of mentions on social media.
Population Growth: Changes in the population size in each region.
Income Levels: Average income or economic prosperity in each region.
Technological Trends: Adoption rates of relevant technologies.
Legal/Regulatory Changes: Any changes that might affect demand.
Health and Safety Concerns: For products affected by health trends.
International Factors: Exchange rates, international trade policies.
Profit features (20 features):
Costs Related Features: Material costs, labor costs, transportation costs, economies of scale, etc.,
Percentage of Demand Satisfied Features (10 features):
Supply Chain Efficiency: Lead time, supplier reliability, production capacity, inventory levels, etc.,
In a typical ML pipeline, the following steps are followed: 1. Data Preprocessing 2. Model Building 3. Model Evaluation 4. Model Deployment
Here we will generate random data to use as features and target values. Targets are the parameters of the LP model. We will use the features to estimate the parameters and solve the LP model. The following Python code generates synthetic data for the features and targets. The data is then split into training and testing sets for each target. The features are stored in a DataFrame for easier manipulation and visualization. The code also demonstrates how to use the AMPL API to solve the LP model.
Code
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressorfrom sklearn.linear_model import Ridgefrom sklearn.metrics import mean_squared_errorfrom sklearn.pipeline import Pipelinefrom sklearn.multioutput import MultiOutputRegressor# Setting a seed for reproducibilitynp.random.seed(56)# Define feature namesdemand_features = [f'demand_feature_{i}'for i inrange(1, 21)]profit_features = [f'profit_feature_{i}'for i inrange(1, 21)]demand_satisfied_features = [f'demand_satisfied_feature_{i}'for i inrange(1, 11)]# Combine all feature names (assuming some overlap for conceptual purposes, but here they'll be unique)all_features = demand_features + profit_features + demand_satisfied_features# Generate synthetic data for featuresnum_samples =100X_data = np.random.rand(num_samples, 50) # 50 features for 100 samples# Creating a DataFrame for features for clearer visualization and manipulationX_df = pd.DataFrame(X_data, columns=all_features)# Generate synthetic targetsy_demand = np.random.rand(num_samples, 4) *100# Demand for 4 regionsy_profit = np.random.rand(num_samples, 4) *50# Profit for 4 regionsy_demand_satisfied = np.random.rand(num_samples, 4) *100# Percentage satisfied for 4 regions# Split the dataset into training and testing sets for each prediction targetX_train, X_test, y_demand_train, y_demand_test = train_test_split(X_df, y_demand, test_size=0.2, random_state=42)_, _, y_profit_train, y_profit_test = train_test_split(X_df, y_profit, test_size=0.2, random_state=42)_, _, y_demand_satisfied_train, y_demand_satisfied_test = train_test_split(X_df, y_demand_satisfied, test_size=0.2, random_state=42)print(f'data frame look like {X_df.head()}\n dimensions are {X_df.shape}')
# Pipeline for demand predictiondemand_pipeline = Pipeline([ ('scaler', StandardScaler()), ('regressor', RandomForestRegressor(n_estimators=100, random_state=42))])# Pipeline for profit predictionprofit_pipeline = Pipeline([ ('scaler', StandardScaler()),# Wrap the regressor with MultiOutputRegressor ('regressor', MultiOutputRegressor(GradientBoostingRegressor(n_estimators=100, random_state=42)))])# Pipeline for demand satisfied predictiondemand_satisfied_pipeline = Pipeline([ ('scaler', StandardScaler()),# Wrap the regressor with MultiOutputRegressor ('regressor', MultiOutputRegressor(Ridge(alpha=1.0)))])# Train each pipelinedemand_pipeline.fit(X_train, y_demand_train)profit_pipeline.fit(X_train, y_profit_train)demand_satisfied_pipeline.fit(X_train, y_demand_satisfied_train)# Making predictionsy_demand_pred = demand_pipeline.predict(X_test)y_profit_pred = profit_pipeline.predict(X_test)y_demand_satisfied_pred = demand_satisfied_pipeline.predict(X_test)# Compile results into a DataFrameresults_df = pd.DataFrame({'Region': ['Region 1', 'Region 2', 'Region 3', 'Region 4'],'Demand Prediction': y_demand_pred.mean(axis=0),'Profit Prediction': y_profit_pred.mean(axis=0),'Demand Satisfied Prediction': y_demand_satisfied_pred.mean(axis=0)})print(results_df)
Region Demand Prediction Profit Prediction Demand Satisfied Prediction
0 Region 1 48.074735 26.214470 29.900298
1 Region 2 44.381077 24.049736 45.463532
2 Region 3 50.392137 23.973054 55.957755
3 Region 4 49.058603 23.533582 47.548125
Code
%pip install -q amplpy matplotlibfrom amplpy import AMPL, ampl_notebookampl = ampl_notebook( modules=["cbc", "highs","gurobi"], # modules to install license_uuid="cf1b53af-8068-4af6-85e2-41060092fde9", # license to use) # instantiate AMPL object and register magics
[notice] A new release of pip is available: 24.0 -> 24.2
[notice] To update, run: /Library/Developer/CommandLineTools/usr/bin/python3 -m pip install --upgrade pip
Note: you may need to restart the kernel to use updated packages.
Licensed to AMPL Community Edition License for <harun.pirim@ndsu.edu>.
/Users/harunpirim/Library/Python/3.9/lib/python/site-packages/urllib3/__init__.py:35: NotOpenSSLWarning: urllib3 v2 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'LibreSSL 2.8.3'. See: https://github.com/urllib3/urllib3/issues/3020
warnings.warn(
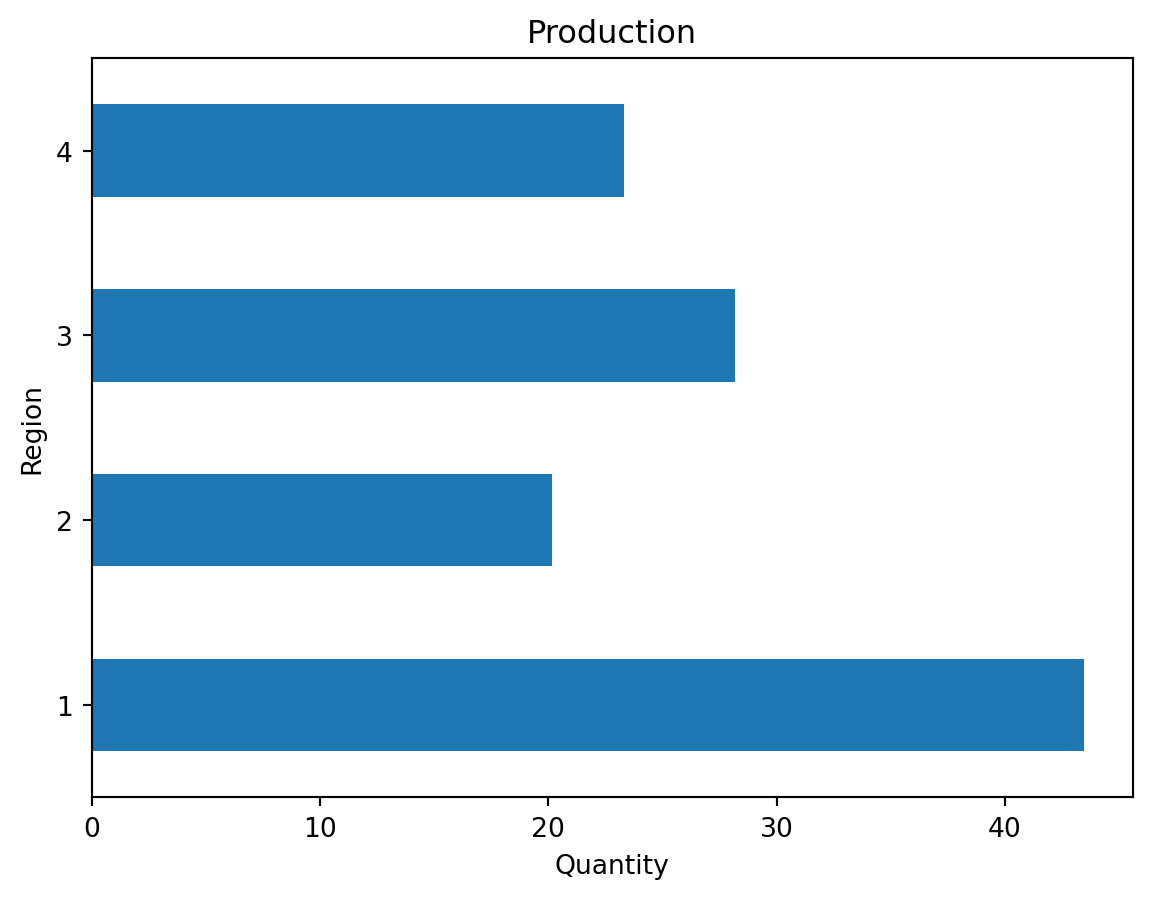
# create a solution reportprint(f"Profit = {ampl.obj['z'].value()}")print("\nProduction Report")for product, Sell in ampl.var["x"].to_dict().items():print(f" For region {product} produced = {Sell}")#plot the resultsproduction = pd.Series(ampl.var["x"].to_dict())plot = production.plot(kind="barh", title="Production")plot.set_xlabel("Quantity")plot.set_ylabel("Region")
Profit = 2849.0191074318773
Production Report
For region 1 produced = 43.44197186598346
For region 2 produced = 20.17720525125885
For region 3 produced = 28.1983081300234
For region 4 produced = 23.32644620961024